
定制高性能GPU粒子系统

【USparkle专栏】如果你深怀绝技,爱“搞点研究”,乐于分享也博采众长,我们期待你的加入,让智慧的火花碰撞交织,让知识的传递生生不息!
这是侑虎科技第1413篇文章,感谢作者 偶尔不帅供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
作者主页:
一、技术设计背景
Unity引擎自带的粒子系统一直是CPU端计算的,这里是指粒子系统以下三大步骤都是在CPU计算。
粒子系统的主要3个开销大的步骤:
1. 每个发射器每帧创建新粒子实例
2. 每个粒子实例每帧更新粒子位置、颜色等状态
3. 每个发射器的绘制提交与发射器之间渲染排序
后来硬件的发展GPU提升的更快,而实际项目中常常也是CPU瓶颈居多。所以有了基于ComputeShader与GPUInstance技术的GPU粒子系统。比如Unreal Engine有CPU和GPU 2套,较新版Unity也有VFX。但是选择自己写一套主要是这几个考量。

基础功能的面板数据
二、单个复杂粒子模式
这种模式虽然游戏内不太常用,但是性能提升最大,也是开发最简单直观的。而且GitHub已经有Demo,我就不重复写这种模式的代码了。如果觉得我这里说的不够详细,没有基础代码部分有点晕的同学可以下载这份很短但完整的源码。
具体的做法分3个步骤:
1. 在C#脚本中,每帧对这个发射器计算这一帧需要创建的粒子数(根据粒子系统上每秒多少个和 Burst参数),然后需要创建多少个Dispatch、多少个线程数,因为这种模式发射器数量很少,粒子数很大,比如全地图烟雾、全图落叶等。所以CPU计算发射数的工作量非常少,没必要让GPU计算。
2. 把这种粒子系统看成粒子数量是固定的,比如N,这N就是粒子系统里粒子上限参数。创建长度为N的StructuredBuffer,存放Particle实例信息的Struct。因为每个实例生命结束顺序不固定,所以需要一个可用粒子池的AppendBuffer来记录Particle数组里哪些Index粒子可被拿来复用。
3. 每帧对所有粒子实例更新,每个ComputeShader线程处理一个粒子实例。所以不管当前多少个粒子在渲染都是按N来做的。这种粒子一般都是循环N,基本就是要渲染的全部,只要设置合理,其实并不会浪费不可见粒子的空循环,比再用Buffer管理有效粒子,渲染时再跳转反而性能更好。
部分关键代码:
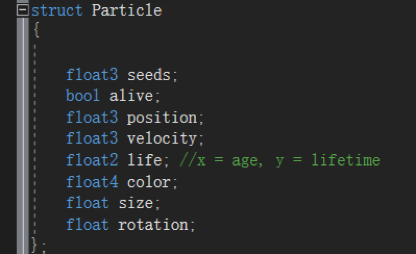
Buff内粒子实例数据
粒子数据与可用粒子对象池索引变量
这里需要注意:dead与alive其实对于C#那边同一份Buffer数据。只是在创建粒子的Kernel里消费,在Init与Update的Kernel里Append,因为死亡或初始化都要把粒子设置为可用,就是把Index还给Buffer。
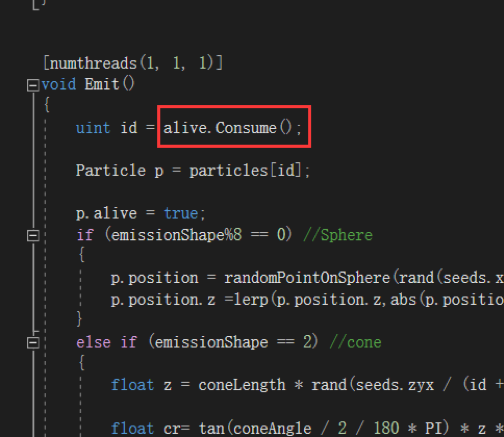
创建粒子是消耗可用的粒子Index
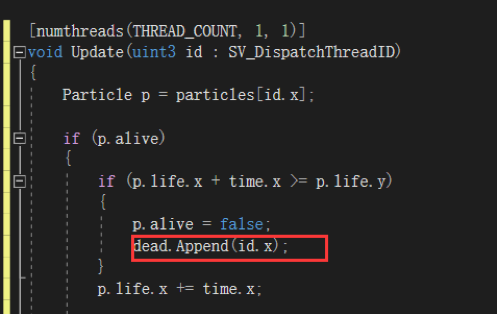
更新时,如果生命到期就把粒子的Index还给可用Buffer
渲染的时候,数量逻辑一样按粒子系统的设置maxCount作为InstanceCount。其中不可见的粒子用col=pInst.alive*pInst.color,实现隐藏。这种模式绝大部分时候绘制的粒子数量就接近maxCount,所以基本都是alive=true的,很少空计算。
以下是测试结果渲染20w个粒子,这种性能提升是巨大的。Unity的CPU方案107帧 VS GPU实现方案1661帧。
颜色不同是因为,Demo的作者在对颜色随生命变化的渐变图转图形时,没考虑用线性空间导致的,不影响性能对比。

单个复杂粒子CPU/GPU方案帧数对比
左边是抓帧证明渲染的粒子数量一样
三、多发射器的简单粒子
这个模式才是我真正为项目开发的模式,也是更能写出性能大收益的模式,老老实实的写很容易负优化。这是因为GPU中的半透明与CPU中的半透明对象很难一起高性能排序,通用引擎为了通用与绝对正确,据我粗略了解,这个问题是无解的(高性能的解),后面会讲如何定制优化,先看性能对比。
单独200个子弹碰撞特效,每个有6个发射器,所以一共1200粒子反射器,但来回切换激活 同时只显示50%左右(后面按每帧600个粒子更新来算)。Unity CPU版是373FPS,本方案是2461FPS。如果用上个方案的那个GitHub Demo之间做这种,会发现只有100多帧,负优化。所以我没有拿那个源码用,而是自己重新设计了一套符合具体项目的方案。

很多发射器实例的模式下
性能对比:Unity CPU粒子(上)
vs 本方案GPU粒子(下)
这是因为单个复杂粒子模式是每个粒子发射器都创建一个含有粒子数据的Buff,每帧通过Dispatch ComputeShader更新这些粒子,也就是说,这样需要600次Dispatch,性能自然就差了。
所以第一步改进就是申请一个公用的大Buff来存放当前激活的所有发射器的粒子数据。对于这种数据组织一般有2种模式:一种是间接寻址,一种是每个粒子发射器定长数组占用,然后通过Offset获取自己在Buffer内的数据。
这里采用第二种,每种发射器最多同时存在32个粒子实例,这样可以满足大部分战斗中反复出现的大量及时性特效。但是我们上面说Particles是根据粒子创建死亡维护的对象池,数据是无序的。当时是同一个粒子发射器,一次DrawIndirect,所以不需要在意顺序。但现在这个数据里有不同的发射器创建的粒子,渲染时也需要访问不同的Index来获取对应数据。所以需要一个RWStructuredBuffer particlesIndexer;来记录每个发射器,包含的粒子在Particles数组中的Index。每个发射器占32位元素,同样渲染的时候,需要用另一个RWStructuredBuffer emitterCounter;,这个变量就是用在 DrawMeshInstancedIndirect(Mesh mesh, int submeshIndex, Material material, Bounds bounds, ComputeBuffer bufferWithArgs, int argsOffset); 这个API里的bufferWithArgs,配合后面argsOffset就能实现每个发射器不同的偏移了。
更新函数中,是这样把当前帧需要渲染的活着的粒子写入这2个Buffer的。
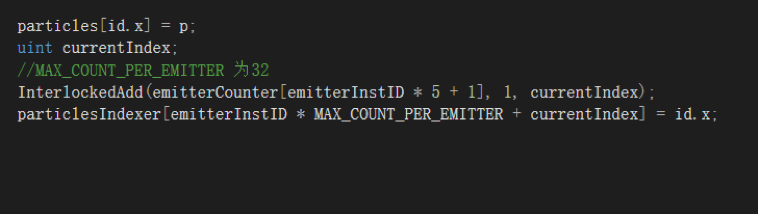
这样虽然每帧对粒子的Update在一次Dispatch后就执行完了,但渲染的时候,每个发射器单独执行DrawCall还是会性能很差。从Nsight工具可以看到非常恐怖的切换Shader次数,时间很快是因为我是3080显卡,在普通显卡中这个性能是不具备现实可用性的。

每个粒子发射器一次DrawCall的GPU切换情况
四、半透明排序与合批渲染
这是整个技术的关键所在也是最大的矛盾点,目前的DrawIndirect API每次调用都只能传一个AABB,引擎会根据这个AABB中心参与场景里其他对象进行排序,所以一次DrawIndirect绘制的所有粒子拥有同一个顺序,要么全部在某对象前,要么全部在某对象后渲染。现在每个粒子发射器单独一个DrawCall的情况下排序正常了(和Unity自带CPU粒子一样,逐发射器排序正常,不考虑多个发射器之间逐粒子排序),但性能不行。
如果所有同材质发射器合并成一个DrawCall,那么排序又会不正常,因为它们中间出现场景的半透明对象无法穿插到这个DrawCall里。这也是为什么Unity的GPUInstance文章都是不拿半透明做例子,因为Opaque的排序不正确不影响画面效果,有Depth保证最终顺序。透明材质是没有写Depth的,除非用了深度剥离技术。但这说远了,一般不会这样做的,所以如何合批是重点。
先看下Unity本身是如何合批粒子的,经过简单测试就能发现,如果ab是相同的粒子发射器的不同实例,c是不同的粒子反射器,ab距离靠近,而c在ab前或在ab后,那么只有2个DrawCall;如果c在ab中间就会有3个DrawCall。所以引擎是排序后才把相邻的又相同的反射器合批渲染。但我们渲染数据是在GPU,如果让CPU排序后要合批,则需要搬运Buffer内数据后合并到一起,很复杂且要改引擎。如果在GPU内排序更不可能,GPU内只能粒子自己排序,无法与场景上对象排序,这些对象都在CPU。所以通用引擎很难解决这个问题。
但做定制开发就轻松多了。首先观察下这些项目中的特效,同一种特效总是出现在世界空间位置相机的地方,比如一个人开枪的特效总是在他枪口附近,而子弹的碰撞特效又总是在前方某个位置,不同的玩家是不同的,所以只要用玩家ID+粒子发射器Prefab种类做Key 来分组,Key相同的一次性渲染就可以了。但这个性能很高,需要牺牲精确度,比如同一个人在玻璃后开几枪,再跑玻璃前面开几枪,那么先创建出的玻璃后的粒子也会一起渲染到玻璃上面。但是这问题不大,因为这些特效都是0.5秒之内就消失的,不会长期停留在跑动和下次开枪时,但墙上的弹孔是个特例他们会停留30秒,所以这个方案不好。
另一个更好的方法是根据世界空间把1立方米内的相同粒子发射器Prefab的所有粒子做一次Draw,因为位置很靠近所以它们按同一个位置参与排序基本是正确的,比较简单的是用long类型把这些信息计算到一起且不重复。假设这里场景范围是正负5000米,全部合批发射器用这个管理 Dictionary activeEmitterTypes;。

根据位置与发射器类型计算合批渲染的编号
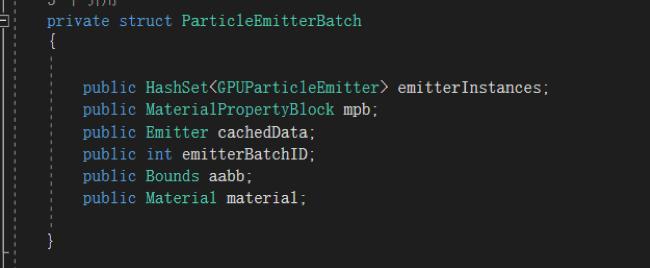
分组发射器数据结构
最后介绍该方案的主要数据。因为改用这种合批,这里有和上面修改的地方。
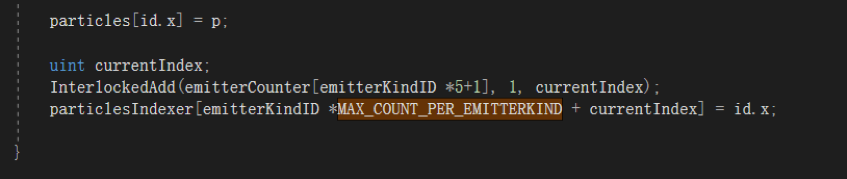
按类型与空间合批渲染的更新方式

该方案的主要数据
最后看下最终落地效果,从原来开枪掉18帧变成只掉5帧,至此优化几轮的开枪降帧问题终于有点稳住了,之前是根本不能与CSGO相比,他们优化的太好了。

最终落地项目
连发35(常见弹夹)后降帧对比
五、GPU的优化
这个GPU粒子主要功能是优化CPU瓶颈,关于GPU的性能优化顺便提下,开火会有大量重叠的多层的大屏幕面积的火焰、烟雾,导致Overdraw问题非常大,观察CSGO与COD有几个简单优化技巧:
文末,再次感谢jackie 偶尔不帅的分享,作者主页:,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
近期精彩回顾
